
Study_note
[AWS] DB Server - DMS - S3 - Glue - Athena 마이그레이션 - ETL - 쿼리 (2) 본문

s3로 마이그레이션된것을 확인했다면 마이그레이션 된 데이터들을 glue를 통해 정제 시키는 과정을 거쳐본다.
우선 glue에서 사용할 역할을 생성해준다.
권한은 AWSGlueServiceRole, AmazonS3FullAccess 넣고 생성
다음으로 glue - crawlers로 이동 후 데이터들을 모으기 위하여 크롤러 생성
임의로 crawler 이름 생성 -> 카탈로그에서 가져오는게 아닌 s3에서 추출 하기 때문에 data stores 선택 -> 폴던 전체에 파일이 필요하기 때문에 all folders 선택
다음으로 파일들이 있는 s3버킷에 폴더경로를 넣어준다.
후 위에서 생성했던 역할 선택 -> 일정은 온디맨드 실행 선택
다음으로 크롤러 데이터베이스를 만들기 위하여 데이터 베이스 추가 후 임의로 이름 지정
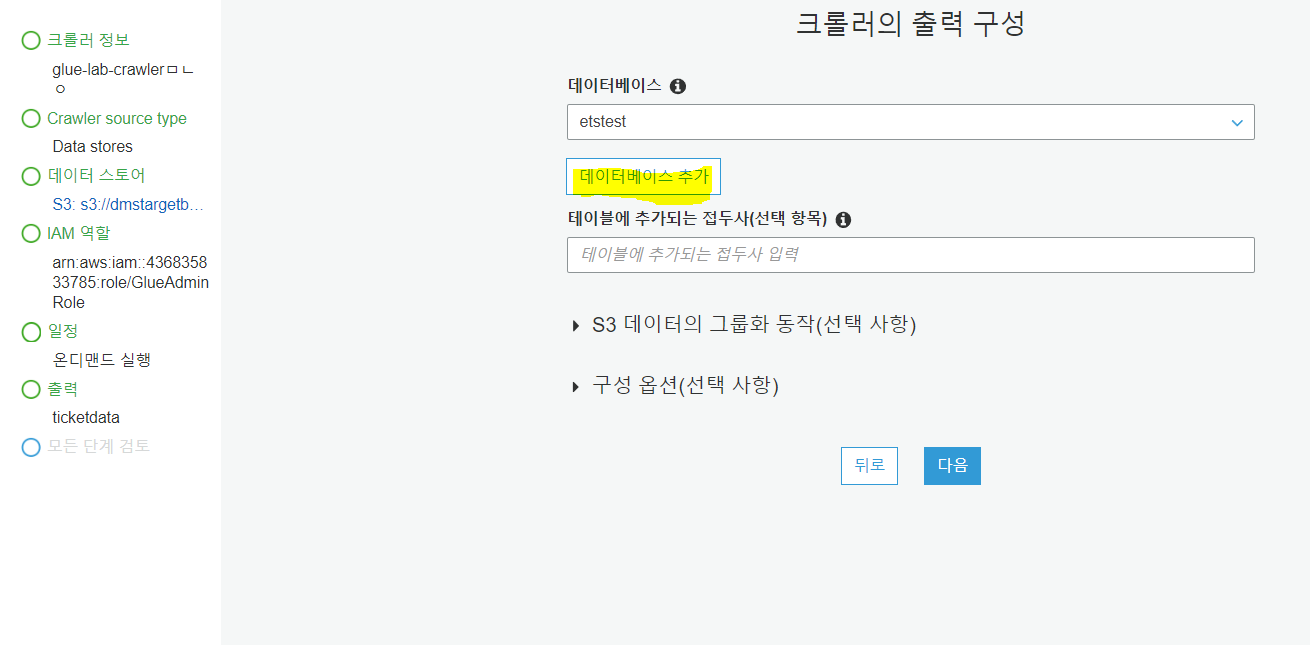
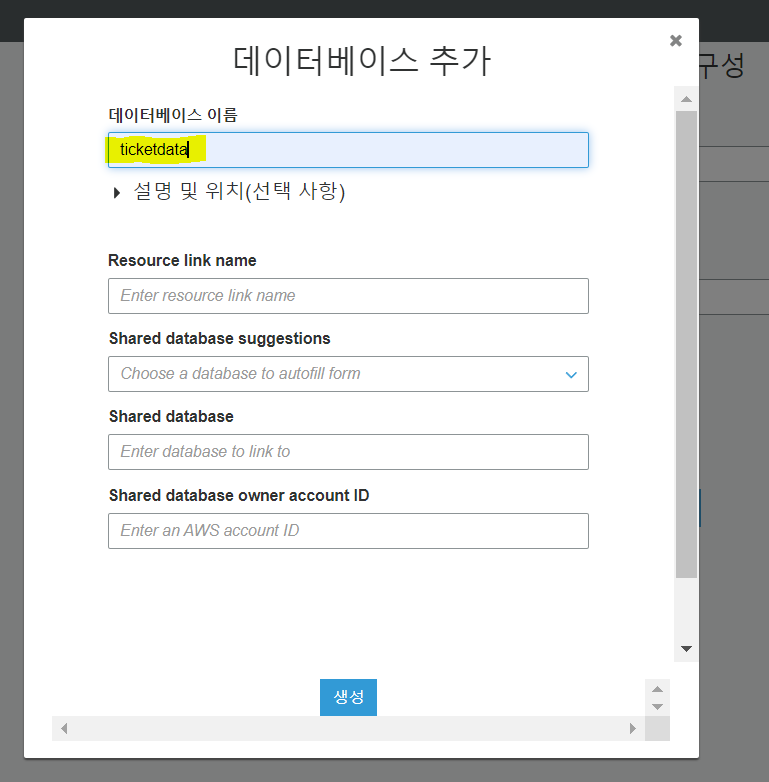
테이블 선택을하면 crawler는 생성되고 콘솔에서 크롤러 실행이 가능하다.
크롤러 실행 하면 s3 저장된 Table의 Metadata를 추출하여 Catalog DB에 저장함을 확인 가능
데이터 베이스 테이블로 넘어가면 S3에 저장된 CSV 파일들에 해당하는 Metadata를 확인

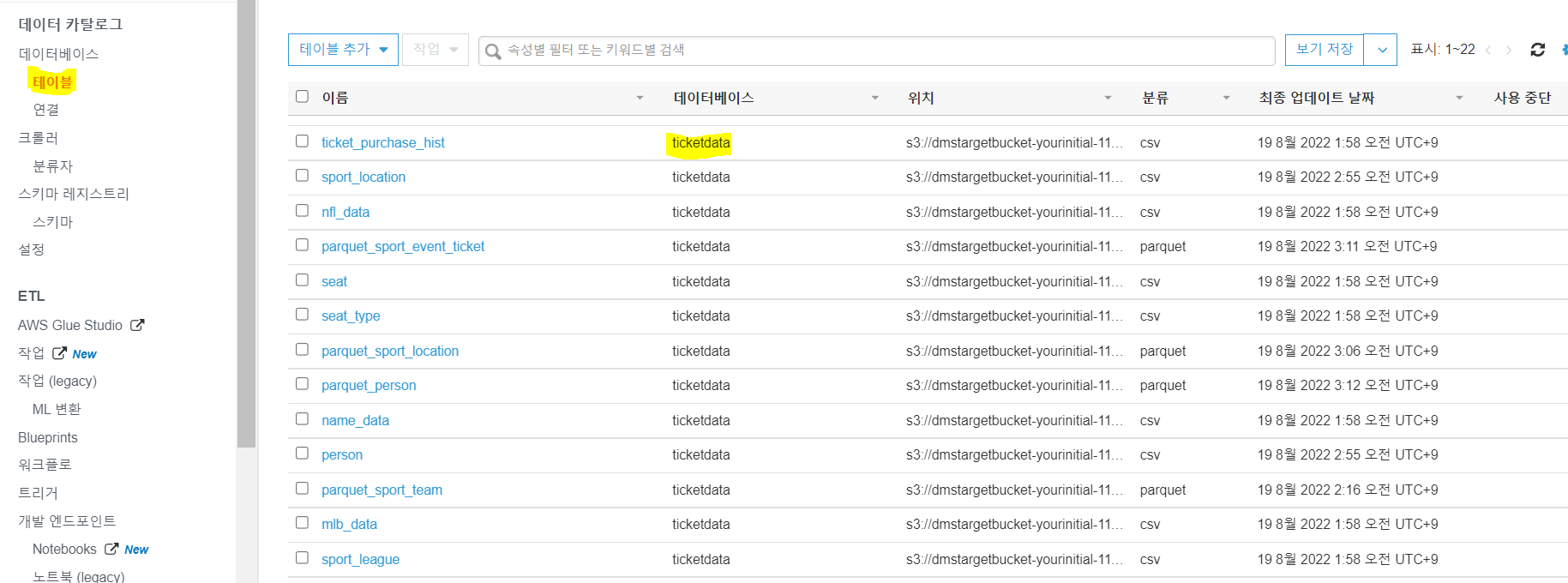
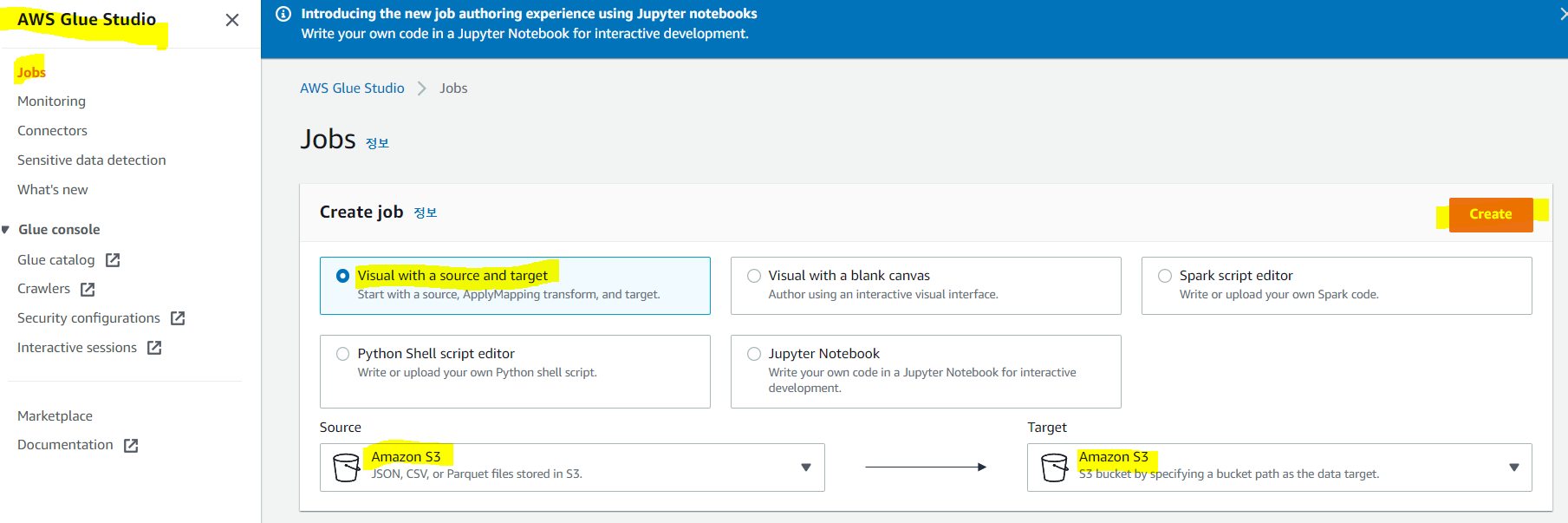
이제 추출했으니 ETL을 하기 위하여 Glue Studio로 이동
Jobs에서 소스 타겟 선택 후 create으로 생성해준다
여기서 소스는 카탈로그로 추출했기 때문에 카탈로그 선택도 가능하면 s3 선택해도 카탈로그 선택란이 있다.
아래 같이 카탈로그 테이블이 선택 가능하면 생성했던 카탈로그 데이터베이스와 변환할 테이블을 선택
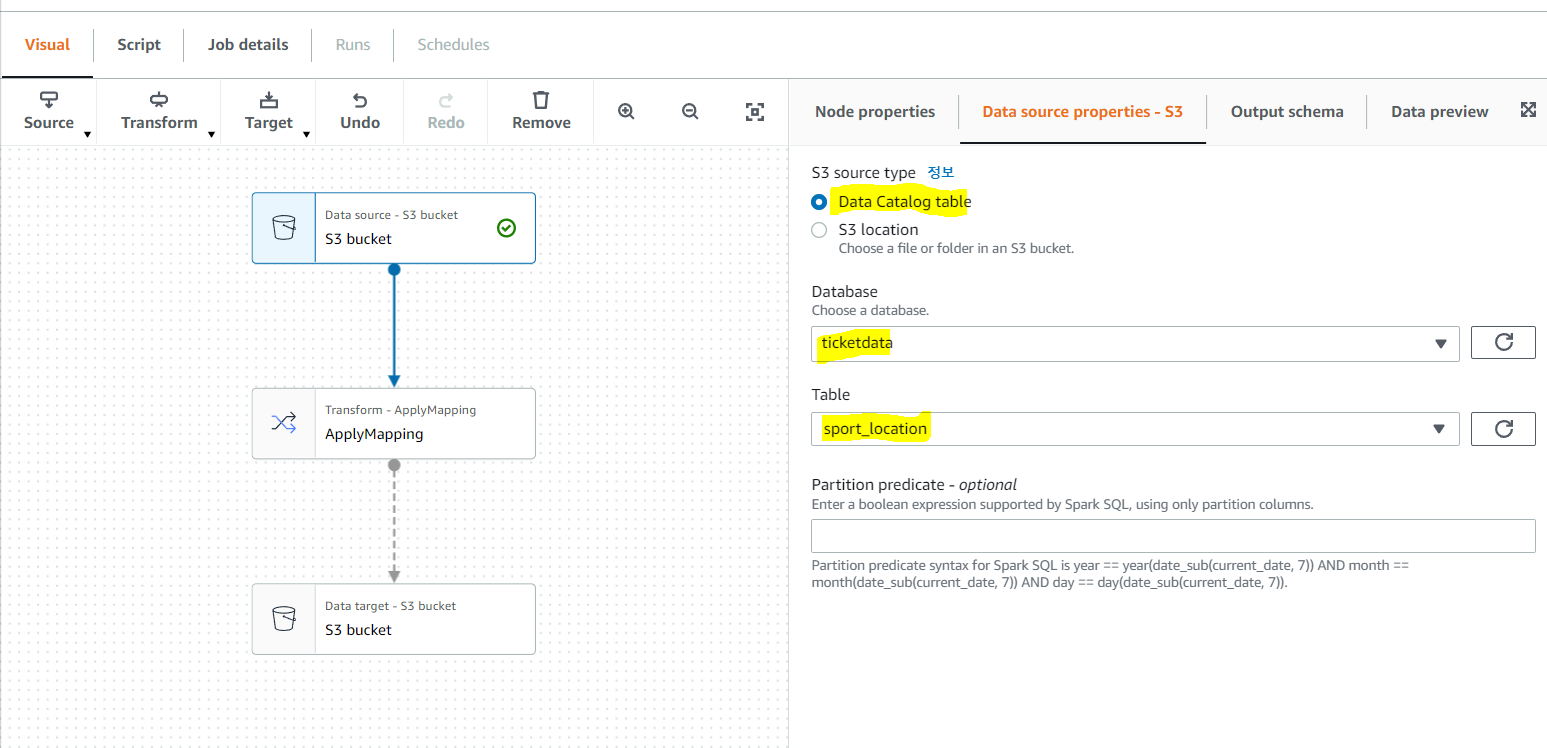
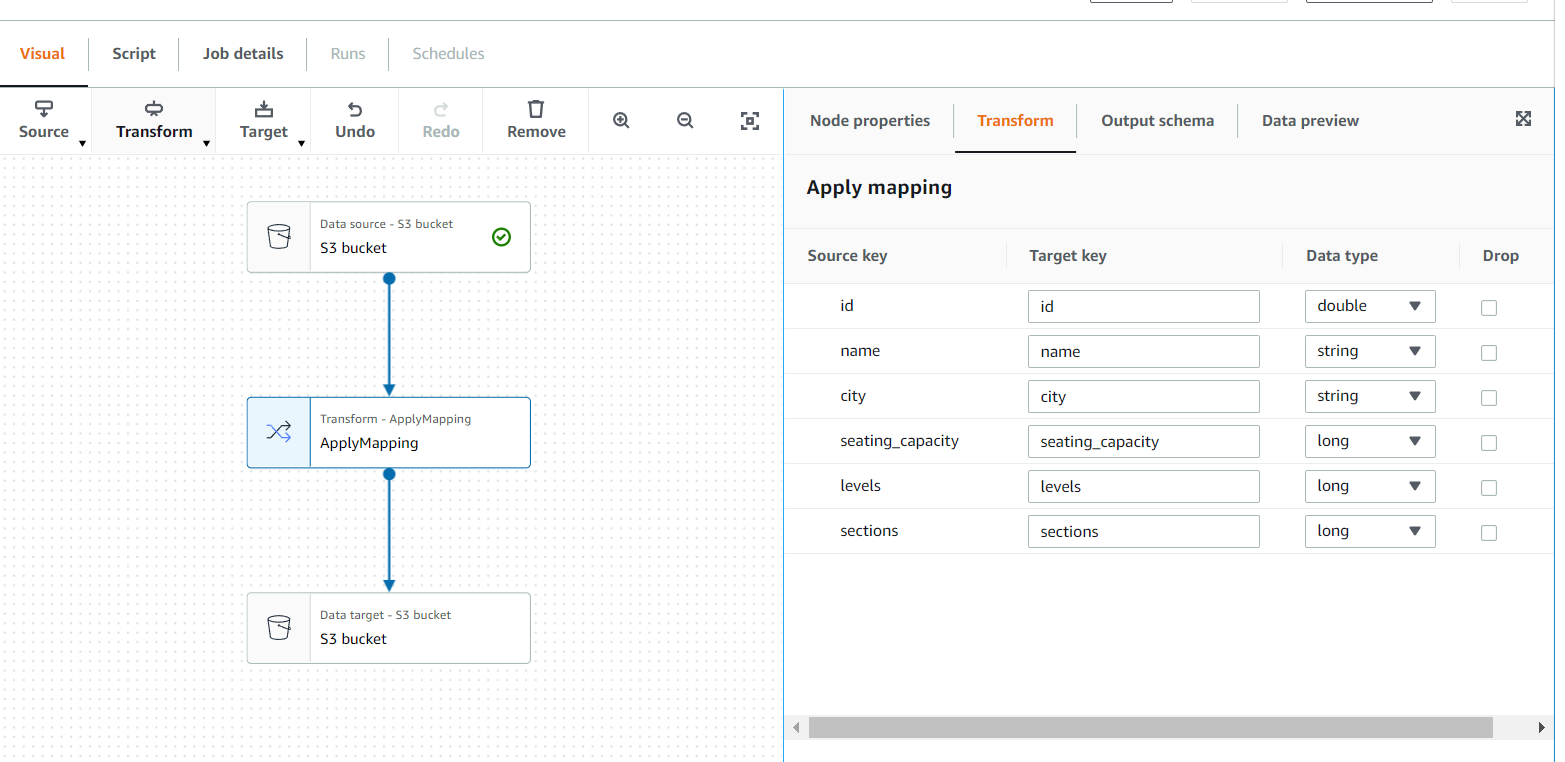
applymapping에서 데이터 값, 타겟 키들을 선택
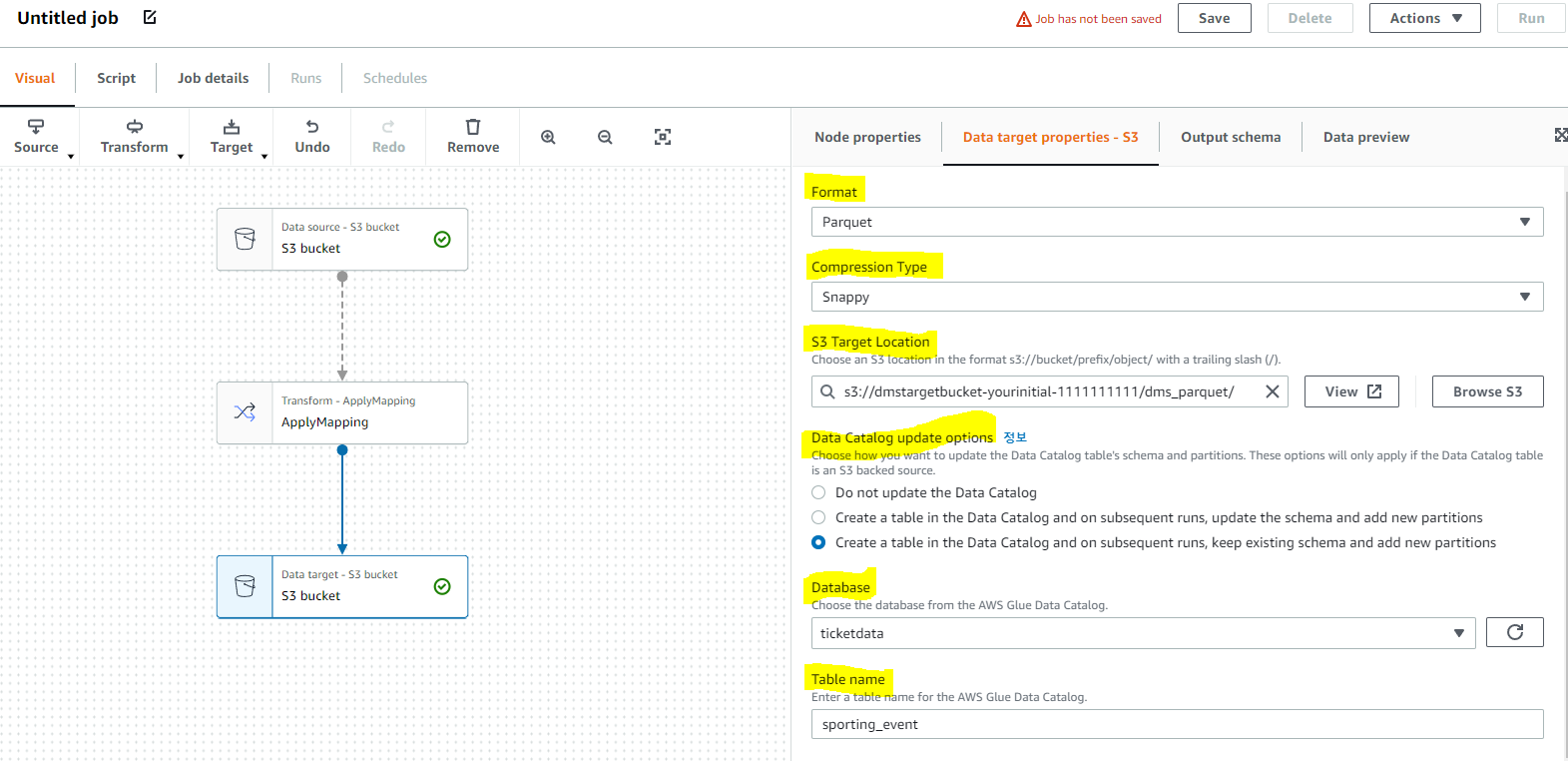
타겟 버킷에서는 변환될 파일의 압축이나 포멧을 어떤 폴더에 저장할지 선택하고 s3 폴더뿐만아니라 glue 카탈로그 데이터베이스 테이블로 저장 가능 하다
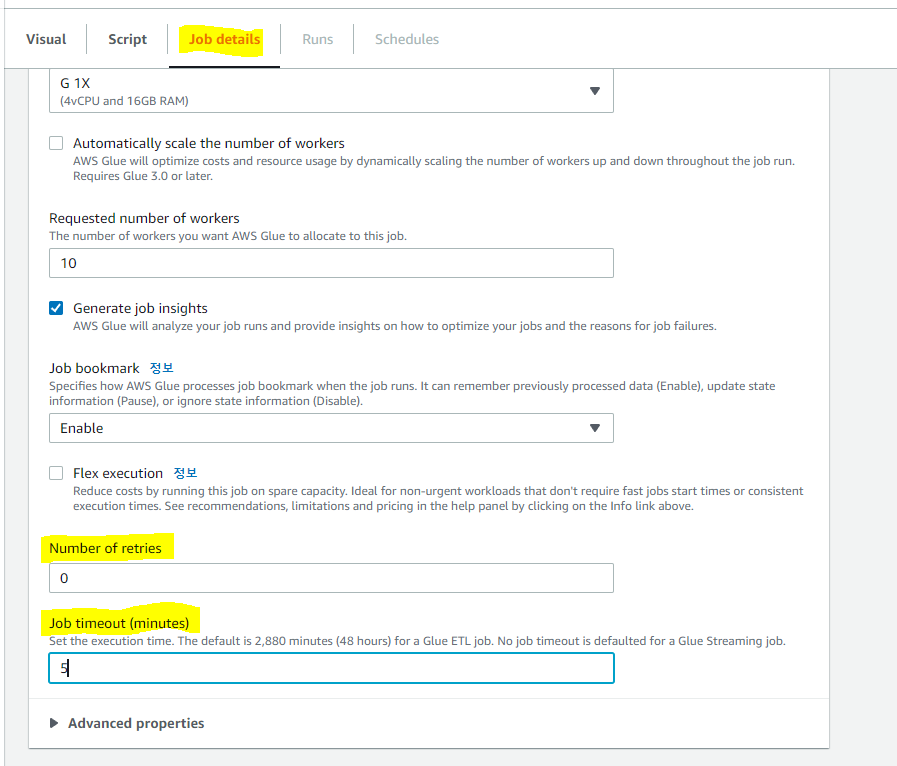
job detail로 이동하면 설정값들 변환하여 보다 빠르게 값 도출 가능
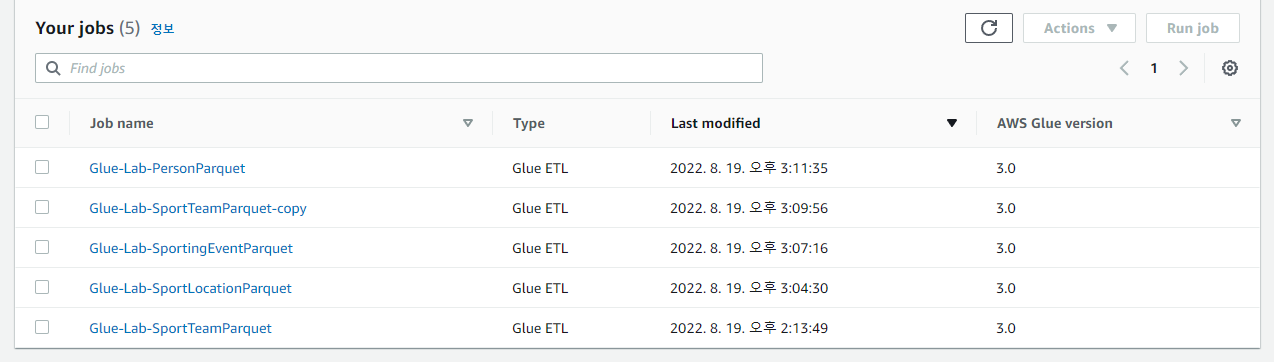
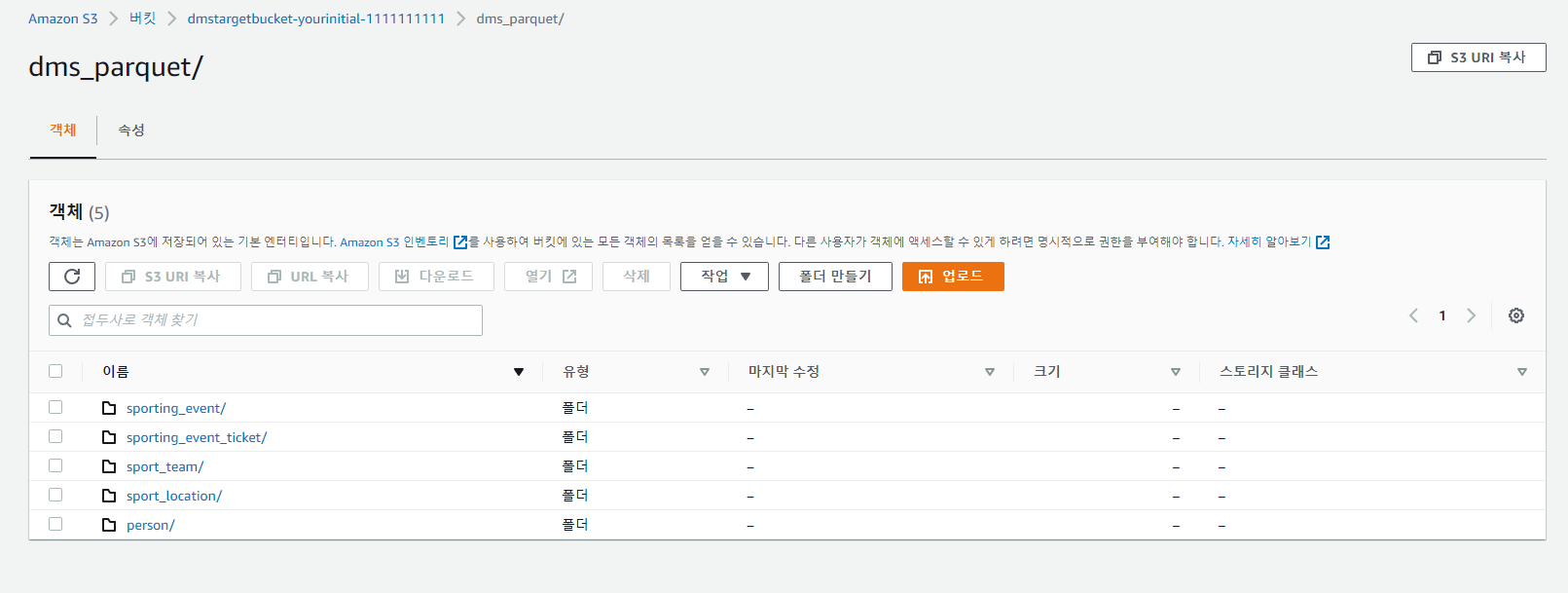
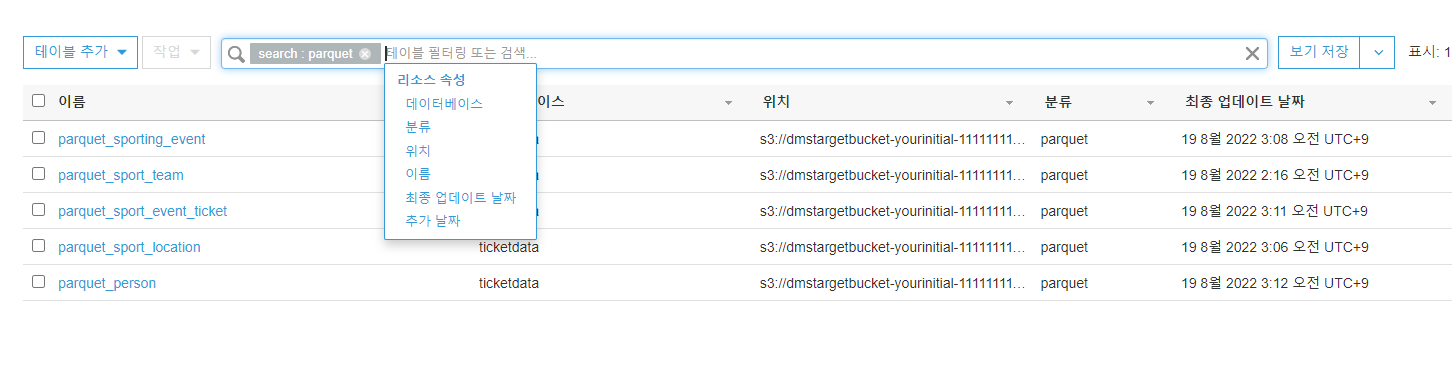
save 후 run 작동하면 아래와 같이 job들이 생성되는 것과 s3 폴더로 생성되는것을 확인할 수 있으며 카탈로그 또한 생성되는것을 확인 가능하다.
(총 5개의 테이블을 ETL 작업을 통하여 저장한것들이다.)
'AWS' 카테고리의 다른 글
| [AWS] Incomplete Multipart Upload 시 미완료 데이터 삭제 (0) | 2023.03.08 |
|---|---|
| [AWS] site to site VPN, 비대칭 라우팅 (1) | 2022.09.20 |
| [AWS] DB Server - DMS - S3 - Glue - Athena 마이그레이션 - ETL - 쿼리 (3) (0) | 2022.08.19 |
| [AWS] DB Server - DMS - S3 - Glue - Athena 마이그레이션 - ETL - 쿼리 (1) (0) | 2022.08.19 |



